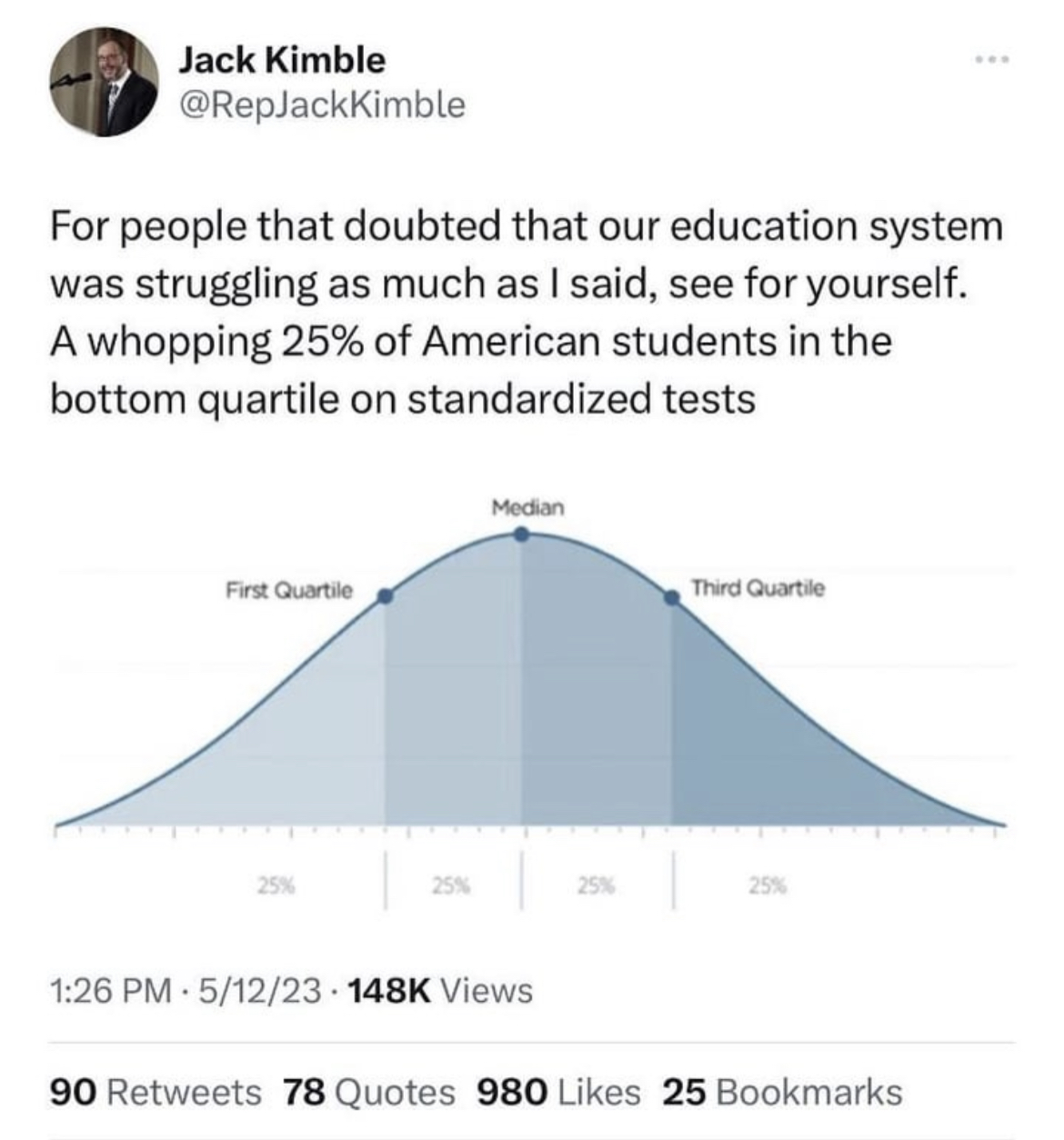
Spendrill is not misunderstanding the OP. He’s just saying that if intelligence could be measured by a better metric, then distribution of that metric among the population would not look as smooth as the one in the OP.
Not if you’re breaking the data into quartiles. Holy shit, do you really think the curve will be any different? Really? All that will happen is that some people will move around in the distribution. And the smoothing does not at all relate to how intelligence is measured but rather how it’s reported - in this graph.
Yes I think it’s very possible that if you were to graph a population’s Intelligence using a some empirical score, then it has a high probability to NOT look exactly like a normal distribution.
For example, let’s say that there was some score called “intelligence score” that scores people’s intelligence from 0-100. Do you think that if you were to graph a given population’s “intelligence score” that it would be EXACTLY centered around 50 in a Normal distribution? I think that’s unlikely. It’s more likely that there would be local maximums or minimums, or various skews in the graph. There could be a small peak at score 75, or a trough at 85. There could be all sorts of distributions.
And guess what? Given this hypothetical distribution, you could STILL draw lines somewhere on the graph showing quartiles. Those lines might not be at 25-50-75. They might not even be the same distance apart from each other. But you CAN draw them somewhere to split the scores. Just because a graph “has quartiles” does not mean it will always look like the OP.


{kind=link}
Spendrill is not misunderstanding the OP. He’s just saying that if intelligence could be measured by a better metric, then distribution of that metric among the population would not look as smooth as the one in the OP.
Not if you’re breaking the data into quartiles. Holy shit, do you really think the curve will be any different? Really? All that will happen is that some people will move around in the distribution. And the smoothing does not at all relate to how intelligence is measured but rather how it’s reported - in this graph.
Yes I think it’s very possible that if you were to graph a population’s Intelligence using a some empirical score, then it has a high probability to NOT look exactly like a normal distribution.
For example, let’s say that there was some score called “intelligence score” that scores people’s intelligence from 0-100. Do you think that if you were to graph a given population’s “intelligence score” that it would be EXACTLY centered around 50 in a Normal distribution? I think that’s unlikely. It’s more likely that there would be local maximums or minimums, or various skews in the graph. There could be a small peak at score 75, or a trough at 85. There could be all sorts of distributions.
And guess what? Given this hypothetical distribution, you could STILL draw lines somewhere on the graph showing quartiles. Those lines might not be at 25-50-75. They might not even be the same distance apart from each other. But you CAN draw them somewhere to split the scores. Just because a graph “has quartiles” does not mean it will always look like the OP.
I think you’re talking past each other — you’re talking about the box plot and they’re talking about the histogram