Ask me about:
- Science (biology, computation, statistics)
- Gaming (rhythm, rogue-like/lite, other generic 1-player games)
- Autism & related (I have diagnosis)
- Bad takes on philosophy
- Bad takes on US political systems & more US stuff
I’m not knowledgeable about most other things
- 24 Posts
- 27 Comments






 2·1 month ago
2·1 month agoMy main social media app is Mastodon (technically Firefish which I will soon migrate to Iceshrimp… but those details are less relevant)
I consider Lemmy less so of a “social media” and more of a link aggregator/discussion forum… but yeah otherwise I try to use Lemmy a bit too. I still browse Reddit quite a lot, but only for individual communities that don’t have equivalents on Lemmy, and I no longer post there
I never used much social media to begin with tbh… I feel pretty decent about the Fediverse. Despite all the drawbacks (blocklists, fedi drama, etc), I think people collectively managed to make an objectively better social media platforms compared to the previous corporation-dominated ones (at least by my personal metrics)
 81·1 month ago
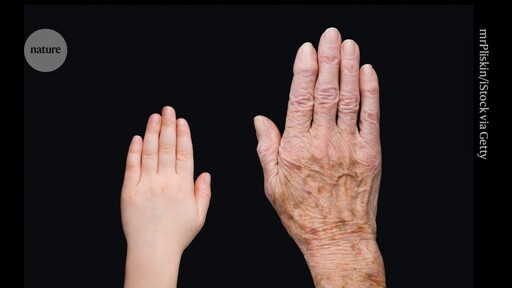
81·1 month agoWell neuroscience isn’t a very old field… More seriously though, I think biomedical scientists know surprisingly little about something if NIH doesn’t fund it… aaand that’s how we understood so little about our own household companions (and a bit too much about cancer. Seriously why do we know so many weird things about cancer much of those don’t even translate into therapeutics)

Reminds me of this post of the same community: https://lemmy.world/post/4492190
 3·2 months ago
3·2 months agoI looked at their individual page (https://www.darkpattern.games/pattern/4/psychological-dark-patterns.html)…
If deleting the game and starting over from scratch sounds like a horrible idea and a waste of your investment, then the game has Endowed Value for you. The more time and money that you invest in the game, the more value it has over a fresh copy of the game.
So I guess they are referring to is something more transactional… for example, if I spent $100 on a gacha game or loot boxes to get a bunch of ultra-rare SSRs. I’d be pretty compelled to keep playing since I’ve already spent so much money on it.
They are not counting, for example, that I get hooked on some weird roguelike game because I genuinely want to get better at it but can stop any time. And if I lose my save file I would still happily start from scratch again (which, hilariously, a pattern named Infinite Treadmill is marked for both Slay the Spire and Balatro… https://www.darkpattern.games/pattern/14/infinite-treadmill.html)
I clearly didn’t drink enough coffee for this before posting
My bad, the original news article did a good job at explaining the missing link… I misunderstood what you were asking
- C-section babies seem to have more immune system-related diseases (https://doi.org/10.1016/j.jaci.2015.07.040), so scientists think they would benefit from special treatment
- Scientists tried to fix this by giving the babies vagina-derived bacteria (https://doi.org/10.1038/nm.4039); couldn’t find any more reports on this but it seems like these don’t work super well?
- This is a proof-of-concept by the lab highlighted in the news (https://doi.org/10.1016/j.cell.2020.08.047), they tried using fecal matter and it worked
- The abstract featured in the news is now a clinical trial that is in progress
I think that’s pretty much it
This is the study they were referring to: https://doi.org/10.1016/j.jaci.2015.07.040
C-section babies have slightly higher risks of several diseases related to immune system function, and the hypothesis is that it is because these babies have slightly less developed immune systems

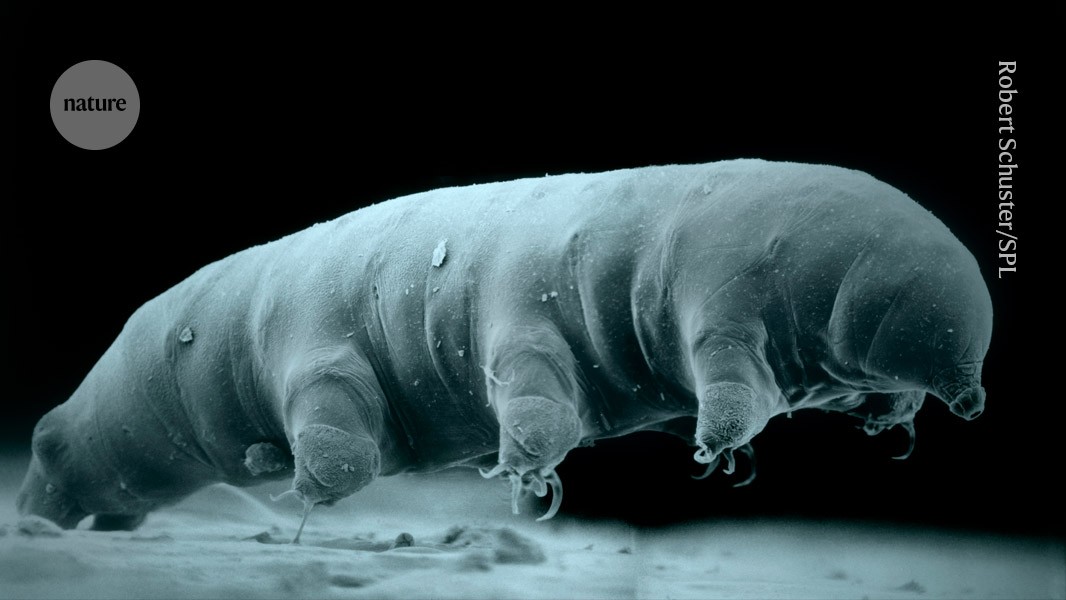

I happen to know a few folks who work in this field (detecting fraudulent scientific papers). This is a bit of an insider knowledge, but there are science sleuths who are fearing for their lives… there might be some seriously shady stuff going on behind research paper mills, but I don’t know who will be the one digging those up.
If it is just on an individual level though methinks Retraction Watch does a decently good job at informing what might or might not be trustworthy
A recent report on Retraction Watch, a PhD student was trying to figure out who’s behind a papermill: https://retractionwatch.com/2024/10/01/hidden-hydras-uncovering-the-massive-footprint-of-one-paper-mills-operations/
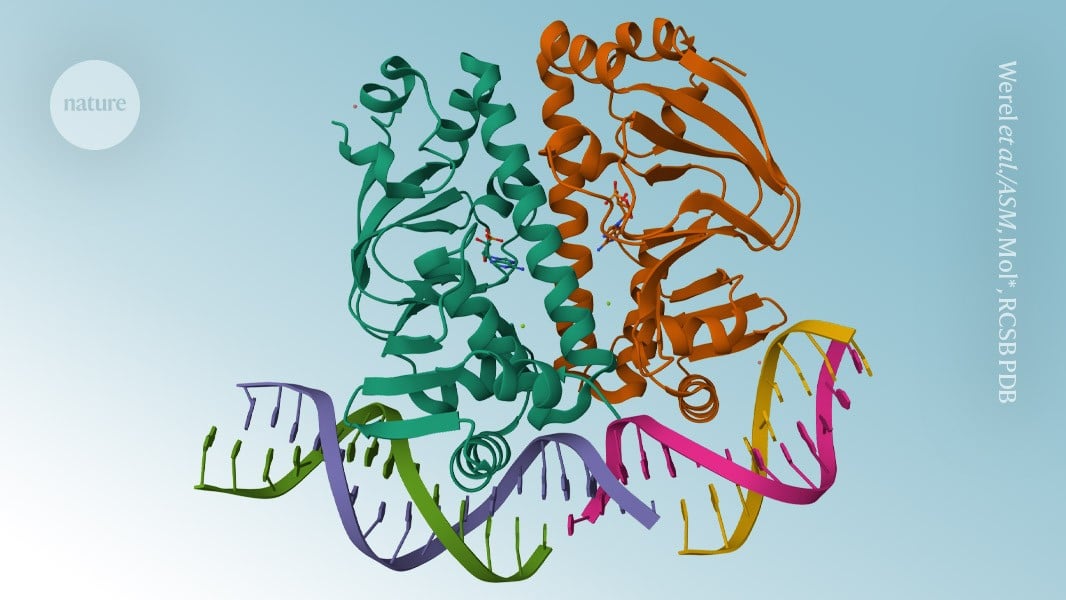
This is from Nature News today: https://www.nature.com/articles/d41586-024-03427-w. Heard a bit about this startup even before so…
Jokes on me, my cats can somehow recognize me from the sound of me walking up to the front door (and only me, not when anyone else is visiting)… No idea if anything can make them not recognize me
 47·2 months ago
47·2 months agoThis again??
This time once archive.org is back online again… is it possible to get torrents of some of their popular data storage? For example I wouldn’t imagine their catalog of books with expired copyright to be very big. Would love a community way to keep the data alive if something even worse happens in the future (and their track record isn’t looking good now)
Pretty sure the “intimate detail” is just the editor being horny… I didn’t make the title don’t blame me
Hehe
Blame the Nature News editor for this, the paper title wasn’t horny at all
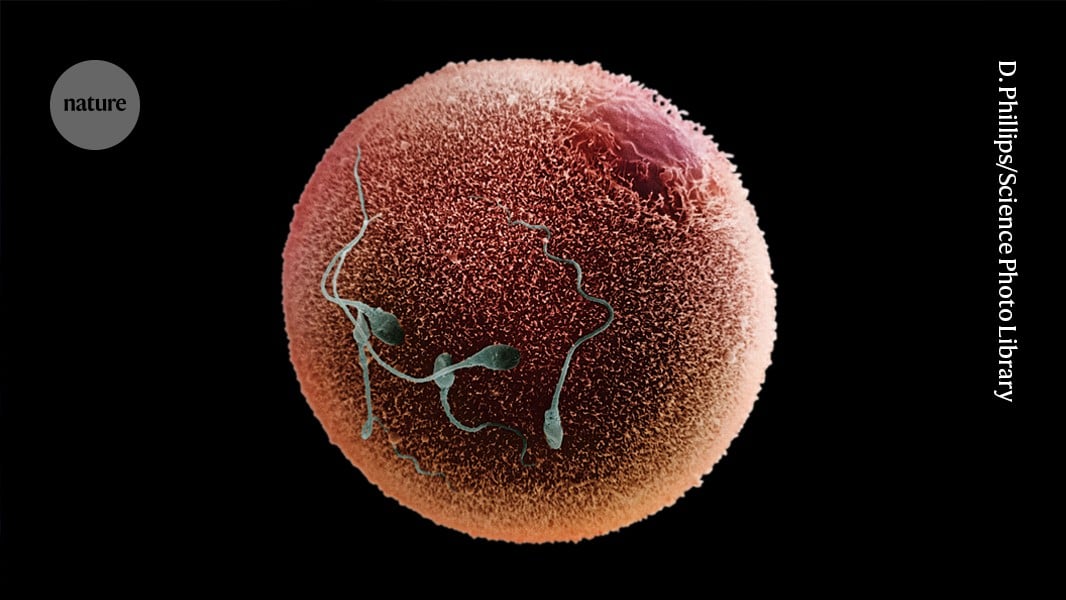

I got curious and wanted to see what method they are using: I believe they are using data from this portal? https://implicit.harvard.edu/implicit/selectatest.html
Looks like anyone can take this! But I guess that also means… did the dyslexics/dyscalculics self-select themselves?
Edit: took one. There is a demographics questionnaire where you can list whether you have disabilities, dyslexia is in there (but not Autism??)… So it is self-selected. And on unrelated note, I am apparently in the 1% that has a strong automatic preference for physically disabled rather than not-disabled people (facepalm
This is a good point… I’m more used to biomedical papers where this author list would be considered typical or even short, but yeah the affiliations seem to state that there are four PIs on this paper which is wild… don’t know what to make of it. If someone knows archaeology better plz inform
I don’t believe anyone mentioned this yet so… here goes nothing, there is a suspicion that this is due to A/B testing
This is a bug report from the Invidious project; this is back in June 6 (so four months ago), but the hoster of a fairly large instance noted a very bizarre error message on the Invidious project…
Conclusion is that Youtube is very likely rolling out A/B testing of requiring all clients to login before viewing videos
Refreshing will probably work considering this is most likely result of an A/B test, but unfortunately I don’t see a way of this problem going away

I genuinely don’t know… there doesn’t seem to be any ongoing discussion of who or why are these people targeting IA. There are other people who are trying to rescue data stored on IA
Hope this would be over soon…

So it was the physics Nobel… I see why the Nature News coverage called it “scooped” by machine learning pioneers
Since the news tried to be sensational about it… I tried to see what Hinton meant by fearing the consequences. Believe he is genuinely trying to prevent AI development without proper regulations. This is a policy paper he was involved in (https://managing-ai-risks.com/). This one did mention some genuine concerns. Quoting them:
“AI systems threaten to amplify social injustice, erode social stability, and weaken our shared understanding of reality that is foundational to society. They could also enable large-scale criminal or terrorist activities. Especially in the hands of a few powerful actors, AI could cement or exacerbate global inequities, or facilitate automated warfare, customized mass manipulation, and pervasive surveillance”
like bruh people already lost jobs because of ChatGPT, which can’t even do math properly on its own…
Also quite some irony that the preprint has the following quote: “Climate change has taken decades to be acknowledged and confronted; for AI, decades could be too long.”, considering that a serious risk of AI development is climate impacts
Oh my… I had a slightly similar incident. New phone number, had a bunch of random strangers texting me (some even calling!) asking for Ethan. My name is not Ethan, I didn’t know who Ethan is
No idea what was on my mind back then, but I somehow got the contact info of this mysterious Ethan, called him (hilarity ensued since he got a call from someone on his contact list named “Me”), confirmed his up-to-date number, and promptly referred everyone looking for Ethan to the real person for over a year…
Life is strange sometimes

A bit off topic… But from my understanding, the US currently doesn’t have a single federal agency that is responsible for AI regulation… However, there is an agency for child abuse protection: the National Center on Child Abuse and Neglect within Department of HHS
If AI girlfriends generating CSAM is how we get AI regulation in the US, I’d be equally surprised and appalled


{kind=link}
{kind=link}
{kind=link}
Based on my understanding of how these things work: Yes, probably no, and probably no… I think the map is just a “catalogue” of what things are, not at the point where we can do fancy models on it
This is their GitHub account, anyone knowledgeable enough about research software engineering is welcomed to give it a try
There are a few neuroscientists who are trying to decipher biological neural connections using principles from deep learning (a.k.a. AI/ML), don’t think this is a popular subfield though. Andreas Tolias is the first one that comes to my mind, he and a bunch of folks from Columbia/Baylor were in a consortium when I started my PhD… not sure if that consortium is still going. His lab website (SSL cert expired bruh). They might solve the second two statements you raised… no idea when though.
Unfortunately… Isn’t there a saying like “the amount of effort to refute bullshit is much large than the amount needed to produce it” or something? So sadly the HCQ thing is just going to stay there for now; the journal taking 4.5 years to retract it didn’t help either