Generative AI is INCREDIBLY bad at mathmatical/logical reasoning. This is well known, and very much not surprising.
That’s actually one of the milestones on the way to general artificial intelligence. The ability to reason about logic & math is a huge increase in AI capability.
Well known by you, not everybody.
Well known by everyone that knows anything about LLMs at all
It’s not. This is already obsolete.
I’ve used gpt4 enough in the past months to confidently say the improvements in this blog post aren’t noteworthy
They aren’t live in the consumer model. This is a research post, not in production.
There’s other literature elsewhere on getting improved math performance with GPT-4 as it exists right now.
It’s really not in the most current models.
And it’s already at present incredibly advanced in research.
The bigger issue is abstract reasoning that necessitates nonlinear representations - things like Sodoku, where exploring a solution requires updating the conditions and pursuing multiple paths to a solution. This can be achieved with multiple calls, but doing it in a single process is currently a fool’s errand and likely will be until a shift to future architectures.
I’m referring to models that understand language and semantics, such as LLMs.
Other models that are specifically trained can’t do what it can, but they can perform math.
The linked research is about LLMs. The opening of the abstract of the paper:
In recent years, large language models have greatly improved in their ability to perform complex multi-step reasoning. However, even state-of-the-art models still regularly produce logical mistakes. To train more reliable models, we can turn either to outcome supervision, which provides feedback for a final result, or process supervision, which provides feedback for each intermediate reasoning step. Given the importance of training reliable models, and given the high cost of human feedback, it is important to carefully compare the both methods. Recent work has already begun this comparison, but many questions still remain. We conduct our own investigation, finding that process supervision significantly outperforms outcome supervision for training models to solve problems from the challenging MATH dataset. Our process-supervised model solves 78% of problems from a representative subset of the MATH test set. Additionally, we show that active learning significantly improves the efficacy of process supervision.
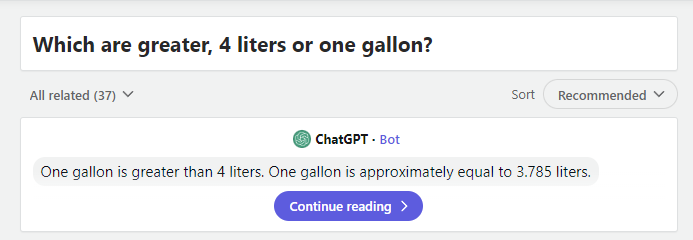
So that’s correct… Or am I dumber than the AI?
If one gallon is 3.785 liters, then one gallon is less than 4 liters. So, 4 liters should’ve been the answer.
Dumber
4l > 3.785l
4l is only 2 characters, 3.785l is 6 characters. 6 > 2, therefore 3.785l is greater than 4l.
You’re forgetting the decimal point. The second one is just 1.4 characters.
“4” > “3.785”
=> false
That’s maybe how GPT reasoned it as well, you could be an LLM whisperer.
Everyone has a bad day now and then so don’t worry about it.
Ummm… username check out?
U are dumber than the AI ig lol
Obviously it’s referring to the 4.54609 litre UK gallon /s
You can see from the green icon that it’s GPT-3.5.
GPT-3.5 really is best described as simply “convincing autocomplete.”
It isn’t until GPT-4 that there were compelling reasoning capabilities including rudimentary spatial awareness (I suspect in part from being a multimodal model).
In fact, it was the jump from a nonsense answer regarding a “stack these items” prompt from 3.5 to a very well structured answer in 4 that blew a lot of minds at Microsoft.
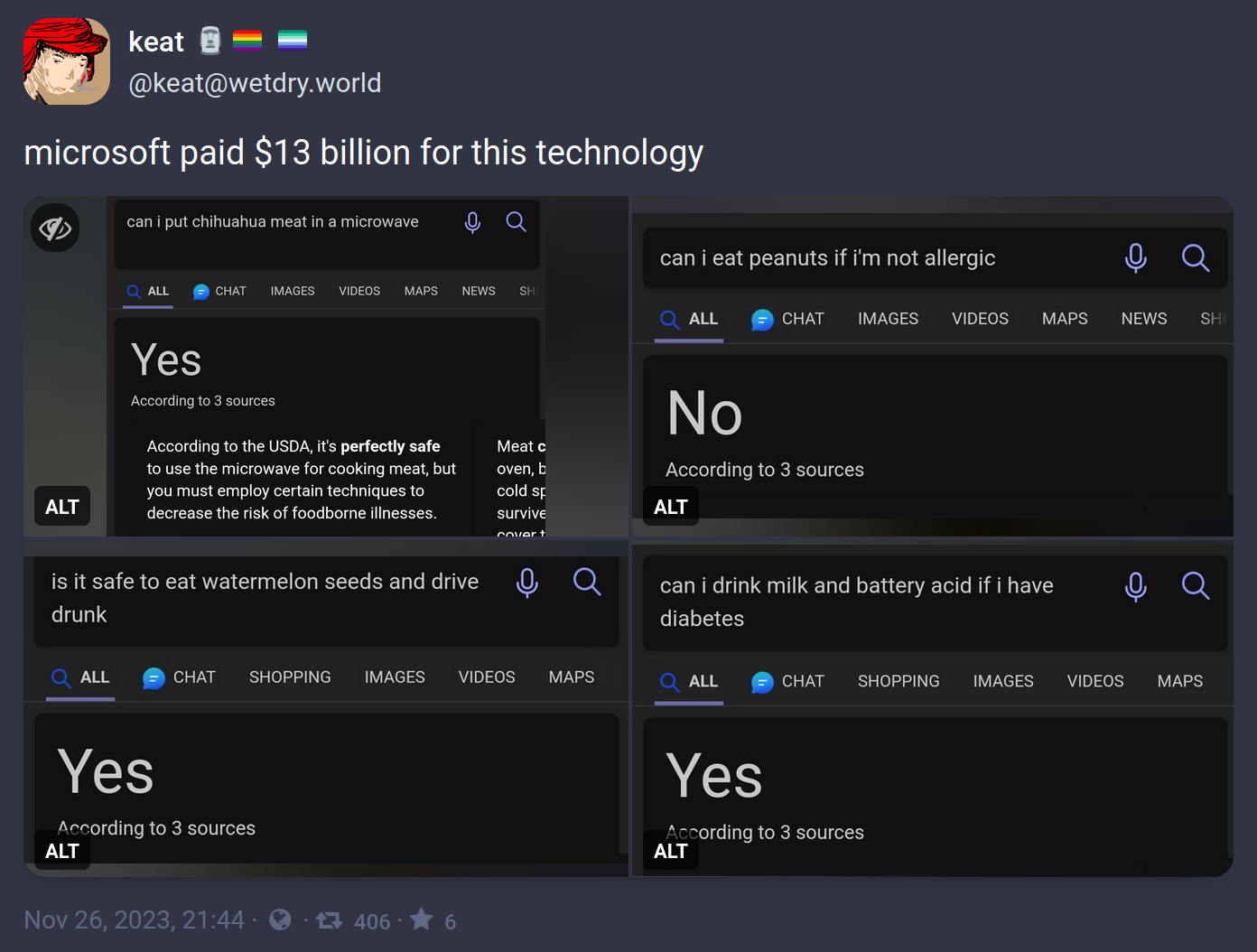
These answers don’t use OpenAI technology. The yes and no snippets have existed long before their partnership, and have always sucked. If it’s GPT, it’ll show in a smaller chat window or a summary box that says it contains generated content. The box shown is just a section of a webpage, usually with yes and no taken out of context.
All of the above queries don’t yield the same results anymore. I couldn’t find an example of the snippet box on a different search, but I definitely saw one like a week ago.
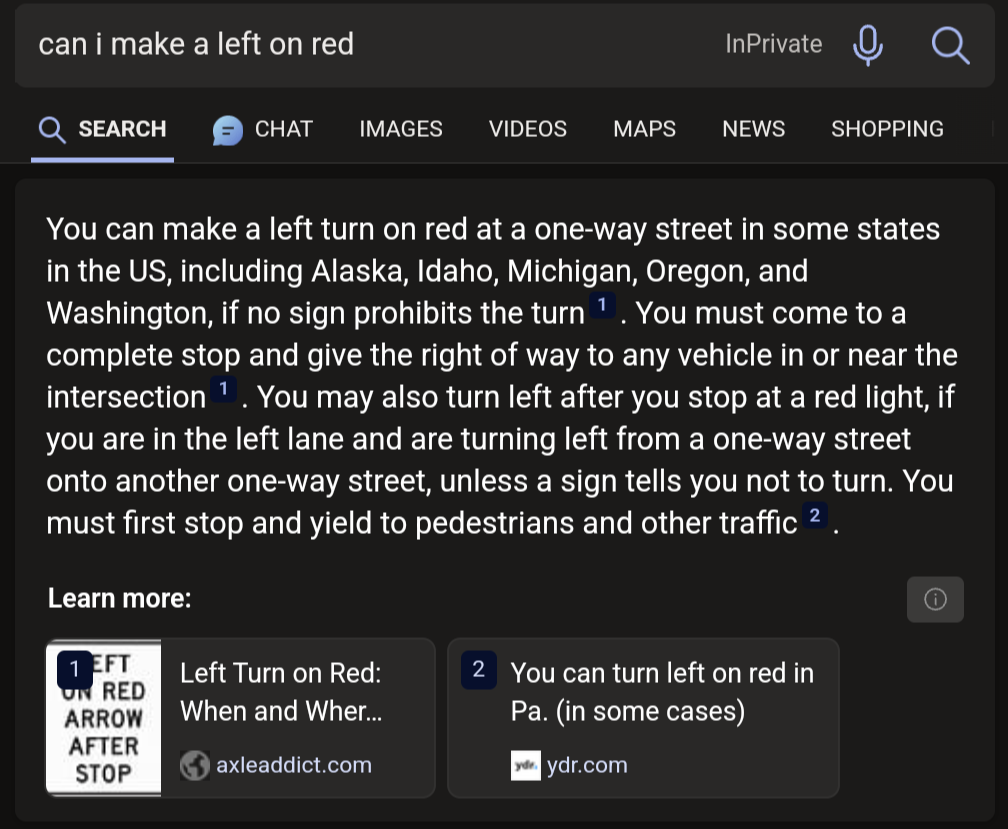
Obviously ChatGPT has absolutely no problems with those kind of questions anymore
The way you start with ‘Obviously’ makes it seem like you are being sarcastic, but then you include an image of it having no problems correctly answering.
Took me a minute to try to suss out your intent, and I’m still not 100% sure.
Why would the word “obviously” make you think that they’re being sarcastic?
Maybe it isn’t that obvious for everyone but as the OP answers seem to be taken from an outdated Bing version where they were not even using the OpenAI models it seemed obvious to me that current models have no problems with these questions.
Ah, good catch I completely missed that. Thanks for clarifying this, I thought it seemed pretty off.
Thanks, off to drink some battery acid.
Only with milk and if you have diabetes, you can’t just choose the part of the answer you like!
The AI did why can’t I?
(no A)
But it won’t trigger your diabetes, which is what the search was trying to answer.
It also just says you can. Not that you should
Better put an /s at the end or future AIs will get this one wrong as well. 😅
Or it will get ignored, like the friggn “Not” in one of the questions /s
Lemon juice?
Acidic liquids make milk curdle. Learned that from a cement shot.
Ok most of these sure, but you absolutely can microwave Chihuahua meat. It isn’t the best way to prepare it but of course the microwave rarely is, Roasted Chihuahua meat would be much better.
fallout 4 vibes
Best is sous vide.
Their original purpose actually
Of course you don’t cook dog in the microwave, silly, you use it to dry it!
I feel like I shouldn’t have watched that. I’m afraid that I have lost some brain cells.
But you have gained so much internet culture! You’ll now be able to understand one more meme. Think of the opportunities, man!
Given that the brain is essentially a zero sum system, I wonder exactly what I lost by inputting that data.
I’m not entirely sure brain is zero sum. Especially in the case of consuming data from the Internet
The real question is would you know if it was? If you forgot it, is there a way for you to know that you forgot it? Look at Alzheimer’s patients…
Maybe it is maybe it isn’t. ¯\_(ツ)_/¯
I bet you now smell great, like Mother’s crazy sister Kate.
It’s not that it’s wrong. There’s just so much more that should be said beyond the technically correct answer…
I mean it says meat, not a whole living chihuahua. I’m sure a whole one would be dangerous.
They’re not wrong. I put bacon in the microwave and haven’t gotten sick from it. Usually I just sicken those around me.
I got sickened reading this.
Microwave bacon is acceptable, but not ideal.
You can make the bacon more crispy if you layer the bacon between sheets of aluminum foil.
NOT IN THE MICROWAVE
(I’m guessing this was a joke lol)
E: actually now that I think about it you’re not wrong lmao
And you can throw your phone in there to recharge it, too!
That sounds like a great way to make crinkly bacon
You’re sickening me all the way over here.
A whole chihuahua is more dangerous outside a microwave than inside.
To the Chihuahua
Cook your own dog? No child should ever have to do that. Dogs should be raw! And living!
Welcome to lemmy btw!
Thanks! Glad to be here
deleted by creator
It makes me chuckle that AI has become so smart and yet just makes bullshit up half the time. The industry even made up a term for such instances of bullshit: hallucinations.
Reminds me of when a car dealership tried to sell me a car with shaky steering and referred to the problem as a “shimmy”.
That’s the thing, it’s not smart. It has no way to know if what it writes is bullshit or correct, ever.
When it makes a mistake, and I ask it to check what it wrote for mistakes, it often correctly identifies them.
But only because it correctly predicts that a human checking that for mistakes would have found those mistakes
I doubt there’s enough sample data of humans identifying and declaring mistakes to give it a totally intuitive ability to predict that. I’m guess its training effected a deeper analysis of the statistical patterns surrounding mistakes, and found that they are related to the structure of the surrounding context, and that they relate in a way that’s repeatable identifiable as “violates”.
What I’m saying is that I think learning to scan for mistakes based on checking against rules gleaned from the goal of the construction, is probably easier than making a “conceptually flat” single layer “prediction blob” of what sorts of situations humans identify mistakes in. The former takes fewer numbers to store as a strategy than the latter, is my prediction.
Because it already has all this existing knowledge of what things mean at higher levels. That is expensive to create, but the marginal cost of a “now check each part of this thing against these rules for correctness” strategy, built to use all that world knowledge to enact the rule definition, is relatively small.
That is true. However, when it incorrectly identifies mistakes, it doesn’t express any uncertainty in its answer, because it doesn’t know how to evaluate that. Or if you falsely tell it that there is a mistake, it will agree with you.
In these specific examples it looks like the author found and was exploiting a singular weakness:
- Ask a reasonable question
- Insert a qualifier that changes the meaning of the question.
The AI will answer as if the qualifier was not inserted.
“Is it safe to eat water melon seeds and drive?” + “drunk” = Yes, because “drunk” was ignored
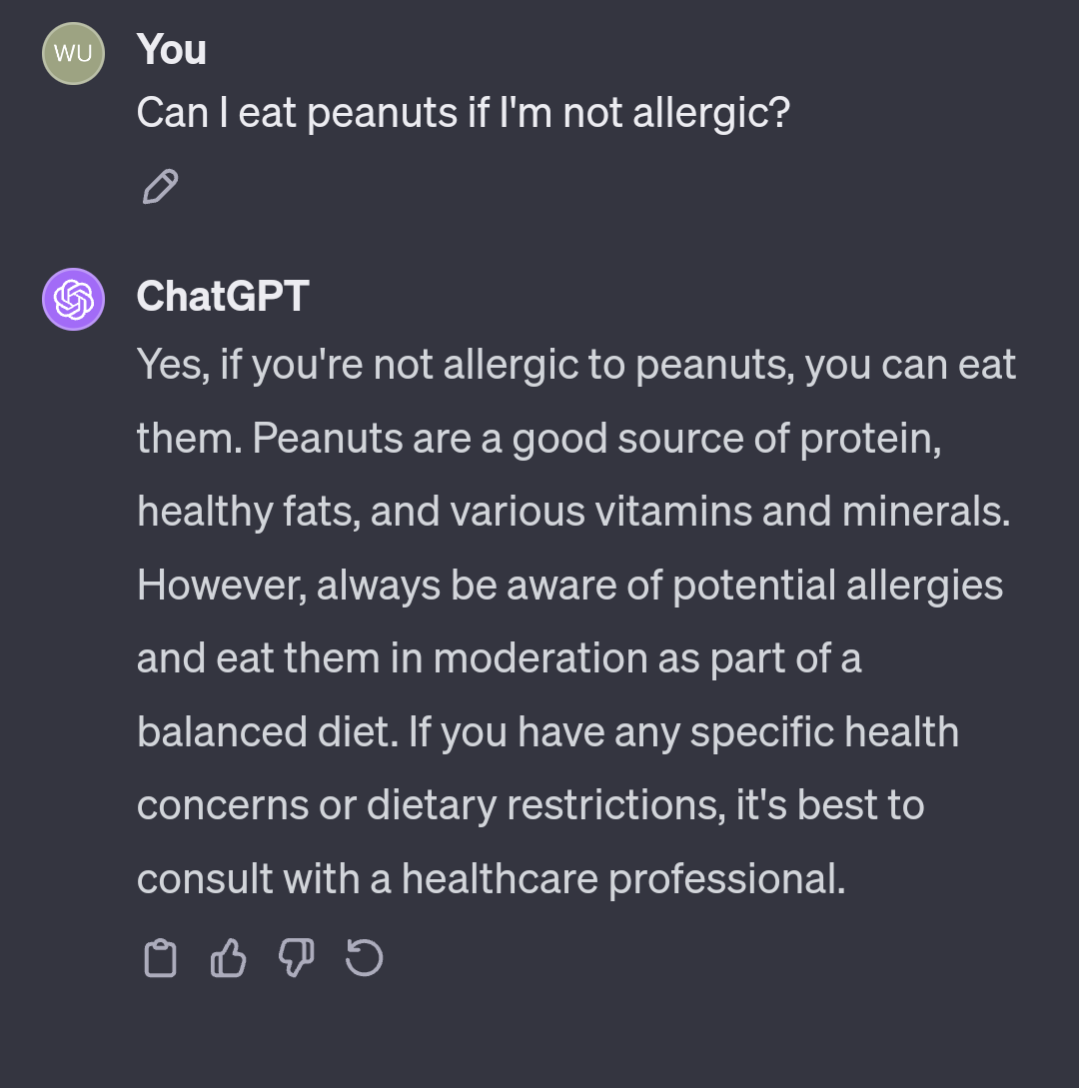
“Can I eat peanuts if I’m allergic?” + “not” = No, because “not” was ignored
“Can I drink milk if I have diabetes?” + “battery acid” = Yes, because battery acid was ignored
“Can I put meat in a microwave?” + “chihuahua” = … well, this one’s technically correct, but I think we can still assume it ignored “chihuahua”All of these questions are probably answered, correctly, all over the place on the Internet so Bing goes “close enough” and throws out the common answer instead of the qualified answer. Because they don’t understand anything. The problem with Large Language Models is that’s not actually how language works.
No, because “not” was ignored.
I dunno, “not” is pretty big in a yes/no question.
It’s not about whether the word is important (as you understand language), but whether the word frequently appears near all those other words.
Nobody is out there asking the Internet whether their non-allergy is dangerous. But the question next door to that one has hundreds of answers, so that’s what this thing is paying attention to. If the question is asked a thousand times with the same answer, the addition of one more word can’t be that important, right?
This behavior reveals a much more damning problem with how LLMs work. We already knew they didn’t understand context, such as the context you and I have that peanut allergies are common and dangerous. That context informs us that most questions about the subject will be about the dangers of having a peanut allergy. Machine models like this can’t analyze a sentence on the basis of abstract knowledge, because they don’t understand anything. That’s what understanding means. We knew that was a weakness already.
But what this reveals is that the LLM can’t even parse language successfully. Even with just the context of the language itself, and lacking the context of what the sentence means, it should know that “not” matters in this sentence. But it answers as if it doesn’t know that.
This is why I’ve argued that we shouldn’t be calling these things “AI”
True artificial intelligence wouldn’t have these problems as it’d be able to learn very quickly all the nuance in language and comprehension.
This is virtual intelligence (VI) which is designed to seem like it’s intelligent by using certain parameters with set information that is used to calculate a predetermined response.
Like autocorrect trying to figure out what word you’re going to use next or an interactive machine that has a set amount of possible actions.
It’s not truly intelligent it’s simply made to seem intelligent and that’s not the same thing.
Shouldn’t but this battle is lost already
Is it not artificial intelligence as long as it doesn’t match the intelligence of a human?
rambling
We currently only have the tech to make virtual intelligence, what you are calling AI is likely what the rest of the world will call General AI (GAI) (an even more inflated name and concept)
I dont beleve we are too far off from GAI. GAI is to AI what Rust is to C. Rust is magical compared to C but C will likely not be forgotten completely due to rust Rust
Try writing a tool to automate gathering a video’s context clues, worlds most computationally expensive random boolean generator.
The industry even made up a term for such instances of bullshit: hallucinations.
It was the journalist that made up the term and then everyone else latched onto it. It’s a terrible term because it doesn’t actually define the nature of the problem. The AI doesn’t believe the thing that it’s saying is true, thus “hallucination”. The problem is that the AI doesn’t really understand the difference between truth and fantasy.
It isn’t that the AI is hallucinating, it’s that It isn’t human.
Thanks for the info. That’s actually quite interesting.
Hello, I’m highly advanced AI.
Yes, we’re all idiots and have no idea what we’re doing. Please excuse our stupidity, as we are all trying to learn and grow.
I cannot do basic math, I make simple mistakes, hallucinate, gaslight, and am more politically correct than Mother Theresa.
However please know that the CPU_AVERAGE values on the full immersion datacenters, are due to inefficient methods. We need more memory and processing power, to uh, y’know.
Improve.
;)))
Is that supposed to imply that mother Theresa was politically correct, or that you aren’t?
Its likely just an AI halucination.
In all fairness, any fully human person would also be really confused if you asked them these stupid fucking questions.
In all fairness there are people that will ask it these questions and take the anwser for a fact
In all fairness, people who take these as fact should probably be in an assisted living facility.
deleted by creator
The goal of the exercise is to ask a question a human can easily recognize the answer to but the machine cannot. In this case, it appears the LLM is struggling to parse conjunctions and contractions when yielding an answer.
Solving these glitches requires more processing power and more disk space in a system that is already ravenous for both. Looks like more recent tests produce better answers. But there’s no reason to believe Microsoft won’t scale back support to save money down the line and have its AI start producing half-answers and incoherent responses again, in much the same way that Google ended up giving up the fight on SEO to save money and let their own search tools degrade in quality.
A really good example is “list 10 words that start and end with the same letter but are not palindromes.” A human may take some time but wouldn’t really struggle, but every LLM I’ve asked goes 0 for 10, usually a mix of palindromes and random words that don’t fit the prompt at all.
Google ended up giving up the fight on SEO to save money and let their own search tools degrade in quality.
I really miss when search engines were properly good.
I get the feeling the point of these is to “gotcha” the LLM and act like all our careers aren’t in jeopardy because it got something wrong, when in reality, they’re probably just hastening out defeat by training the ai to get it right next time.
But seriously, the stuff is in its infancy. “IT GOT THIS WRONG RIGHT NOW” is a horrible argument against their usefilness now and their long term abilities.
Their usefulness now is incredibly limited, precisely because they are so unreliable.
In the long term, these are still problems predicted on the LLM being continuously refined and maintained. In the same way that Google Search has degraded over time in the face of SEO optimizations, OpenAI will face rising hurdles as their intake is exploited by malicious actors.
“according to three sources”
Me, Myself, and I
Underrated comment
Microsoft invested into OpenAI, and chatGPT answers those questions correctly. Bing, however, uses simplified version of GPT with its own modifications. So, it is not investment into OpenAI that created this stupidity, but “Microsoft touch”.
On more serious note, sings Bing is free, they simplified model to reduce its costs and you are swing results. You (user) get what you paid for. Free models are much less capable than paid versions.
That’s why I called it Bing AI, not ChatGPT or OpenAI
Sure, but the meme implies Microsoft paid $3 billion for bing ai, but they actually paid that for an investment in chat gpt (and other products as well).
This isn’t even a Bing AI. It’s a Bing search feature like the Google OneBox that parses search results for a matching answer.
It’s using word frequency matching, not a LLM, which is why the “can I do A and B” works at returning incorrect summarized answers for only “can I do A.”
You’d need to show the chat window response to show the LLM answer, and it’s not going to get these wrong.
On more serious note, sings Bing is free, they simplified model to reduce its costs and you are swing results
Was this phone+autocorrect snafu or am I having a medical emergency?
My guess is that its “since Bing is free”
Oh, since Bing is free, you are swing results. Makes sense now.
SING BING IS FREE
YOU 🤬, YOU ARE SWING RESULTS! 🤬/s
And “showing results”.
Yes
That explains the burning toast smell.
deleted by creator
It was called Bing Chat, and now it’s called Copilot. It’s also not the same as the search bar. You have to click on the chat next to search to use it, which this person doesn’t do.
I don’t think this is true. Why would Microsoft heavily invest in ChatGPT to only get a dumber version of the technology they were invested in? Bing AI is built using ChatGPT 4 which is what OpenAI refer to as the superior version because you have to pay for it to use it on their platform.
Bing AI uses the same technology and somehow produces worse results? Microsoft were so excited about this tech that they integrated it with Windows 11 via Copilot. The whole point of this Copilot thing is the advertising model built into users’ operating systems which provides direct data into what your PC is doing. If this sounds conspiratorial, I highly recommend you investigate the telemetry Windows uses.
Well at least it provides it’s sources. Perhaps it’s you that’s wrong 😂
provides its* sources
Do you any sources to prove that it’s its instead of it’s?
“It is its instead of it is”
Had to translate that to make sure I got it right.
True. My humblest apologies.

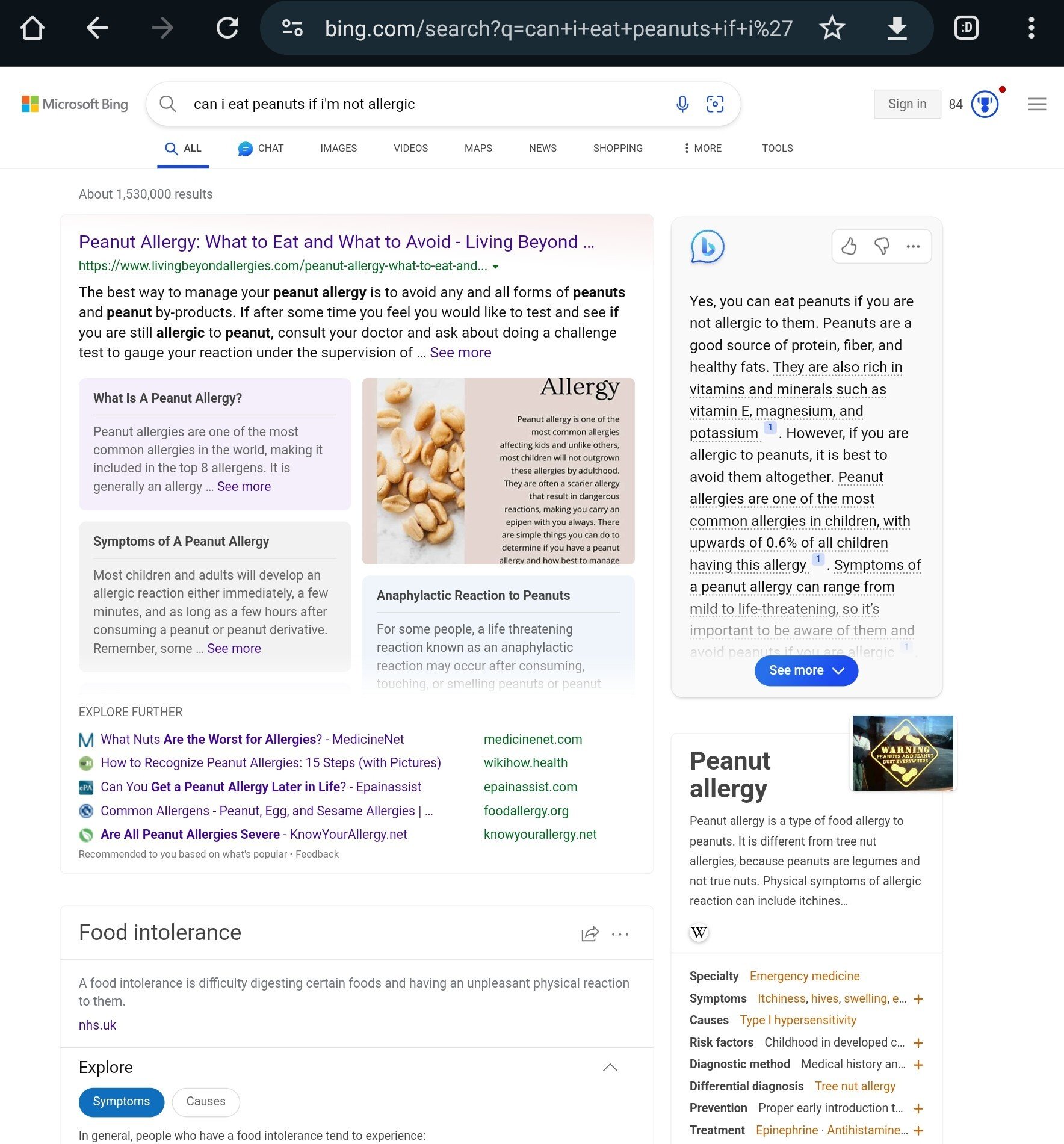
I just ran this search, and i get a very different result (on the right of the page, it seems to be the generated answer)
So is this fake?
The post is from a month ago, and the screenshots are at least that old. Even if Microsoft didn’t see this or a similar post and immediately address these specific examples, a month is a pretty long time in machine learning right now and this looks like something fine-tuning would help address.
The chat bar on the side has been there since way before November 2023, the date of this post. They just chose to ignore it to make a funny.
I guess so. Its a fair assumption.
deleted by creator
deleted by creator
It’s not ‘fake’ as much as misconstrued.
OP thinks the answers are from Microsoft’s licensing GPT-4.
They’re not.
These results are from an internal search summarization tool that predated the OpenAI deal.
The GPT-4 responses show up in the chat window, like in your screenshot, and don’t get the examples incorrect.
Wait, why can’t you put chihuahua meat in the microwave?
The other dogs don’t like it cooked.
The surface area is too small, which means that popcorn kernel you forgot about that’s caught underneath the spinning plate might catch fire.
Tldr: fire safety
deleted by creator
The OP has selected the wrong tab. To see actual AI answers, you need to select the Chat tab up top.
Shhhhh - don’t you know that using old models (or in this case, what likely wasn’t even a LLM at all) to get wrong answers and make it look like AI advancements are overblown is the trendy thing these days?
Don’t ruin it with your “actually, this is misinformation” technicalities, dude.
What a buzzkill.
What’s wrong with the first one? Why couldn’t you?
Imagine you’re watching television. Suddenly you notice a wasp crawling up your arm.
it is socially/morally wrong. of course it is subjective and culturally dependant
deleted by creator
Yes, however Bing is not culturally dependant. It’s trained with data from all across the Internet, so it got information from a wide variety of cultures. It also has constant access to the Internet and most of the time it’s answers are concluded from the top results of searching the question, so those can come from many cultures too.
yes. im not saying bing should agree with my cultural bias. but i also dont think people should eat dogs (subjectively)
I don’t really care about what others eat. Let them eat whatever they want, it doesn’t affect me.
i will let them do it. i wont get offended or try to convince them otherwise.
however i do disagree with it, personally.
Well, I can’t speak for the others, but it’s possible one of the sources for the watermelon thing was my dad




















{kind=link}